
WANT SCHOOL BLACK IN YOUR INBOB? Sign up for our alestal newsletters for only to receive is the most true for prison ai, data, and security guards. Subscribers now
Chinese E-Commerce Raes’ Alibba has Waves Glopty in the Tech and Business stores with his family of “qenmododos (laith model), beginning of the 20th Qwen 3 In April 2025.
For what?
Since the studies lunch are not only customers, including it was convicting to the folters that take advantage of compolit, celebrating the fucketing. Think of them as an alternative for the deeply deeply.
This week, Alibaba team has released the last updates to his qew family, and they appreciate the attention of Ai Power users in the west for their top. In a case it has the New Kimi-2 model from the rival chinese ai launches moonhot, published in the middle of 2025.
AI IMPACT series will go to San Francisco – 5. August
The next phase of AI is here-are you ready? Join chiefs from blocks, Gsk, and sap for an exclusive look, like autonomous agents to do the recovery settings – of real-time-tivtivation.
Secure your place now – space is limited: https://bit.ly/3gfffllff
The New Qweeen3-235B-A22B 2507-instruct Model – Published on AI Code Sharing Community Hanging face take part A “floating point 8” or FP8 versionwhich we have more in-depth below – improves the original qwen 3 in the reasoning tasks, the actual accuracy and more cheerful understanding. It is also outperformant Claude open 4 “Do not commit about” version.
The New Qwee3 Moderatid also delivers as better cooperating results with users settings and general supplies. But that doesn’t last?
Read for what it offers Enterprise users and technical decision.
FP8 version lets the Entradorsess QWen 3 running and calculate a distant fewer memory
The “FP8” version of 1-bit floating point compresses the numeric operations to use fewer memory and without using noteworthy.
In practice, what means this aches with[weasaabdariansubstancesforlesserlyhardwareormoretolearnlearnaboutaremoreundifficientandmoreinthecloudTheresultismoresubstitutingperiodreadhigher-energycostsandabilitytoneedthedevillationswithoutamassiveinfrastructure
This makes the FP8 Model especially attractive to the production environment with closely lincry or cost-constraints. Teams are qen3’s skills on Singre-node cats or local developmental machines for massive multi-gpu cluster. There is a barrister with private eMYING, where energy and energy projects in particular insalit project.
Though Qwwu’s Reconcirizity of the Apponian Bank’s Refresh Freague Freiger FRIISS FRISS, later FP9 be quantified. Here is a practical illustration (Updated and correctly to 07/2/23/2025 at 16:04 PM it – This piece originally included. I apologize for the mistakes and thank you readers to contact contact me about them.:
| Crises | BF16 / BF16-Equiv Build | FP8 quasated build |
|---|---|---|
| GPU memory used* | ≈ 6 640 GB total (8 × H100-80 GB, TP-8) | ≈0 g |
| Single-demanding inference speed † | ~ 74 tokens / s (batch = 1, context = 2 k, 8 × H20-96 GB, TP-8) | ~ 72 tokens / s (same settings, 4 × H20-6 GB, TP-4) |
| Power / energy | Full nodes of eight H100s pull ~ 4-4.5 kw under exposure (550-600 w pro card, plus host) ‡ | FP8 needs a half cards and move half the data; NVIDIA FPSR FP8 Case-Studies Report ≈ 39-40% lower TCO and energy at comparable passable bypass |
| GPUS needed (practical) | 8 × H100-80 GB (TP-8) or 8 × A100-80 GB for parity | 4 × H100-80 GB (TP-4). 2 × H100 is possible with aggressive off-charging, at the cost of the strings |
*Disk footprints for checkpoints: Bf16 weights are ~ 500 gb; The FP8 checkpoint is “WAS 200 GB, so the absolute memory saving in GPU most of the waves. Not from wander not from wear of wear of weights, not of weights, don’t know alone.
† Speed Figures Figures FRUE3 officials Splangn Benchmarks (Batch 1). Bypass scale are almost linearly with Batch size: Based measured ~ 45 tokens / s per user in batch 32 and ~ 1,4 k TPU paru8 setup.
‡ No Vendor Deliveries Exact Wind-Power numbers for QWen, so we are about H100 Board PPIE8 PPIGIT8 PPIGITE ENCIGITY ENCIGIC ENCIGIC ENCIAN
No more ‘Hybrus rationale’ … instead, Qwen bounds separate reasoning
Maybe the most interesting, qen has announced that it is no longer pursuing a “hybrid” your approach that it has entered with QWen 3 in April. It has shined by an approach of the sovereign Ai collectively nous researchIn the.
This allows users to flag to at a “reasoning” model, leave AI model and his own self-control and to make the chain of-thought (cot) before replying.
Suddenly it was designed to mimic the abilities to disable the skills of powerful proprietary modes as the Recrtiotai “O1, o4-mini-mini-high
However other than the rival models that always engages in such a “reasoning” for all prompts, qenm 3 or, the user’s “or, the user can be” before “before their prompts,
The idea was users check to commit the slower and more tokin-inzing thinking mode, to make more difficult prompts and tasks and tasks. But also once set that the tear the tours to the user decide the user. While flexible, it also designs.
Now as qen written on x:
“After talking with the community and thought it thought we decided to stop the hybrid derhy-one. At the Instructing the Instructor’s separate, for the best quality.”
With the 2507 update – an instructor or non-basic model, for the moment – AleiBaba is no longer stincinet and a single model. As separate to send, the individual modify individuals since the optimessen charts in which options, system, regasments.
The result is a model that they are closer with user instruction, generically generative responsibilities and, as a benchmar coats
Performance Benchmarks and used cases
In comparison with his forefathers, QwENT3-235B-A22 Instruution-state string
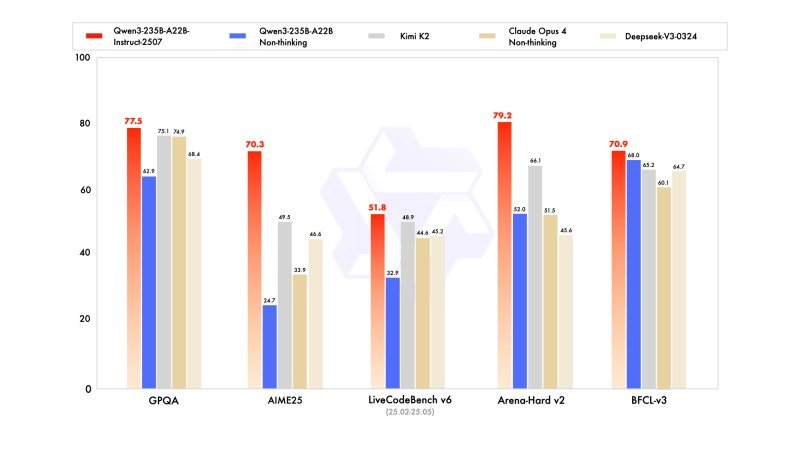
- Mmmlu-per scores increase by 75.2 to 83.0a notable profit in general knowledge.
- GPQA and SuperGPQA benchmarks improve by 15-20 percent pointstreads over stronger well accuracy.
- Justification tasks such as Aime25 and ARC-AGI show more than double the previous performance.
- Code generation improveswith livecoding biteings raising scores from 32.9 to 51.8.
- More-speaking assistance widerchopped by improved coverage of long-flood language and better alignment over dialect.

The mode keeps a mixture of the experts (moe) architecturer, active 8 out of 128 experts at the AM member Bankbrities – 230 billion perimeters.
As mentioned, the FP8 version provides you fine grass quantalization for better inference speed and reduce memory.
Enterprise-ready by design
In contrast to many open-source llms who often posted under restored research rides or the API access for commercial use, qen3 is quasix.
Bay a Permissive Apache 2.0 license, this means entry is it free for commercial applications. They can also:
- Deploy Models local or by Openai Compatible Apis with Valm and Sglng;
- Fine-tune models privately used to explop lora or qlora without proprietial data;
- Log and inspect all eligible and outputs and the premises for compliance and audits;
- Scale of the prototype in production with dense variants (of 0.6B to 32b) or mode checkpoints.
Alius is also described Qins, a light of equipment, which make good center, which were built instructed the user.
BENCHMARKS such as dew-commerce and BFCL-v3 suggestions the instructional model can perform proficiency that execute multi-step decision-of-typical of the purpose-built agents.
Community and Industry reactions
The release is already getting well from AI Power users.
Covered paulAI Circle and Founder of Private Lilm Chatbot Host Blue shell ai, are inspected On X An enlistment card shows QWEEN3-235B-A222Bruptting-2507 Outper Opy Opius 4 and Kimi-HPQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA, APQA “Even more powerful than kimi k2 … and even better than auush open 4.”
Influenced Nik (@ ns123abc) Comment on his rapides impact: “QWen-3-235B did Kimi K2 irrelevant after only one week, in spite of a quarter of the size, and you smile.”
Meanwhile, Jeff Budder, Head of Product at Hugging Facelit the deployment benefits: “Qwhish quiet a massive improvement in Qweeen3 … It will be best at (Kimi K2, a 4x greater model) and closed (CLUSMS 4) lrms.”
He has the availability of a FP8 checkpoint for faster inference, 1-click Deployment on azure ML and support via MlX to MAC or INT4.
Theostatically go 2. Aner Secret contribution are like the model of the performance and ceregrifitic reading in Foby.
What’s next for QWen team?
Alibaba is already laying for the groundwork for future updates. A separate commentary fee model is in the pipeline, and the QWen Roadmap shows on increasing agency systems of long-horizons task.
The multimodal support, as as a as said in QWEEN2.5 -00 -00–00–e-2 in Belgium are also available to explore.
And already, rumors and rumblings started as qweee team members still another update and their model family, their web properties URL URL strings for a new Qween3-Code-480b-EN35B-instruct model, probably a 480 billion parameters with a token amount of 1 million.
What with qen3-235b-A22-Instruasians ran at the age of the Benps, such which infultation systems, but a wildplanal systems.
The flexibility of light exhibit crossing of the indicative performance and address-friendly license of a single edge in an additional line.
For teams intended the sorting instructions-fruit seller and their ai and their ai – without the limitation of seller-in or USWEx-based painters – shuffles.



